What is the future of Data Labeling and how it matters?
Over the years, authors of science fiction have created vivid images of future societies in
which robots and artificial intelligence (AI) are integral parts of daily life. Nowadays, it is
feasible to deploy AI because of the technological advancements that have been created. AI
is pervasive, addressing issues in business, manufacturing, customer service, medical, and
even people’s everyday lives.
Another element that has been crucial in this case, in addition to advancements in
processing technology and internet infrastructure, is the accessibility of big data and data
labeling services. In this blog article, we’ll examine the part data labeling services play in
improving AI and influencing the future.
Data Labeling: What is it?
It takes a lot of data to develop AI. When developing AI, researchers attempt to replicate
the human learning process. Machine learning is a whole branch of AI science that is
devoted to this procedure.
Data labeling and data annotation are the same thing. Both terms refer to the same method
of annotating text, video, and images with the aid of specialized text annotation software
and image annotation tools.
Data labeling is the process of preparing unprocessed data for AI creation. Using specialist
software tools, it entails tagging and labeling the data with relevant information. The type of
data used can vary depending on the AI use case – text, images, and videos can all be
improved through proper data labeling.
Labeled vs Unlabeled Data
The accuracy of the data utilized to train AI models is crucial. The data collection that
accurately depicts reality is referred to as “ground truth” in AI data science. It is the
foundation for a future AI platform’s training. Future AI workflows will be impacted if the
ground truth is faulty or wrong.
Developers spend a lot of time choosing and curating training data because of this.
Gathering and assembling training data is thought to account for 80% of the work put into
an AI project.
The “Human in the Loop” paradigm (HITL) has been a constant in AI research over the years.
The key theory guiding the development of AI is its potential to displace people from risky,
monotonous, and time-consuming tasks.
One of the paradoxes of AI development is that some of its most important components
need a lot of manual labor. Data labeling is the primary illustration. You need high-quality
data sets to develop algorithms that are more effective and error-free.
Advent of Data Labeling Services
Services for data labeling are necessary to “teach” algorithms how to recognize particular
items. Businesses employ a variety of cutting-edge ways to create training data sets. One
method effectively provides software eyes to observe the world, while the other offers it
the ability to comprehend spoken and written language from people. They have already had
a significant impact on modern human life as a whole.
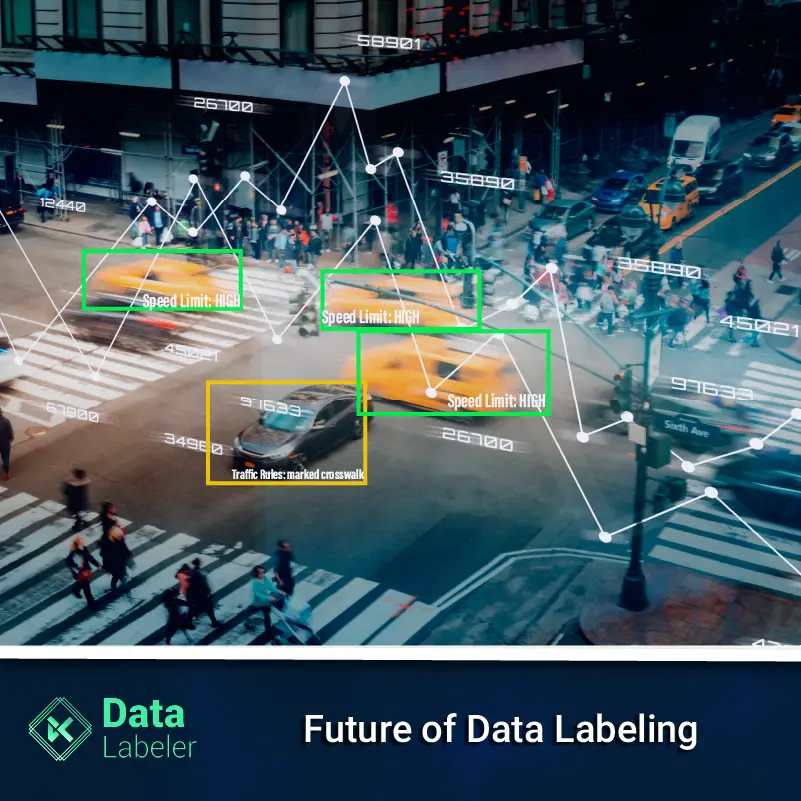
- Bounding Boxes: For Object Detection
- Polygons: For Semantic & Instance Segmentation
- Points: For Facial Recognition & Body Pose Detection
- Texts: For Image Captioning
- Select: For Image Classification
- Semantic Segmentation: For More Complex Image Classification
Wondering how Data Labeler can help you?
Data Labeler digitally delineates and identifies an object in an image or video so that the AI
can later learn to recognize it. To increase its capacity to correctly identify the object
without any tags in the future, the AI needs a wide variety of samples of tagged data
because objects like vehicles can arrive in a variety of shapes, sizes, and colors.
Our data labeling specialists have many hours of expertise working on computer vision,
natural language processing, and content services projects for the geospatial, financial,
medical, and autonomous vehicle industries.
Contact us for the best Data Labeling Services !
 admin
admin
 August 08, 2023
August 08, 2023