

Creating quality labeled datasets for machine

Creating quality labeled datasets for machine
No minimum purchase and spend requirements

Industry specific workforce
Global client base

Quality assurance features
Flexible, feasible and customizable

Empowering underserved communities

Unlimited Support to ensure your datasets meet your expectations
Join us as a Labeling Partner or Become a Reseller
We are proud to say that we have a huge and ever-growing client base, spanning across the entire globe.
We cater to multiple industries thereby covering a massive footprint.
We have undertaken over 200 plus projects with a dedicated team and by offering flexible solutions.
We cater to an international audience, well equipped to handle challenges and creating a foothold for our brand.

We have a team of more than 1000 (and growing) full time Data Labelers. Data Labeler specializes in creating, Sustainable growth
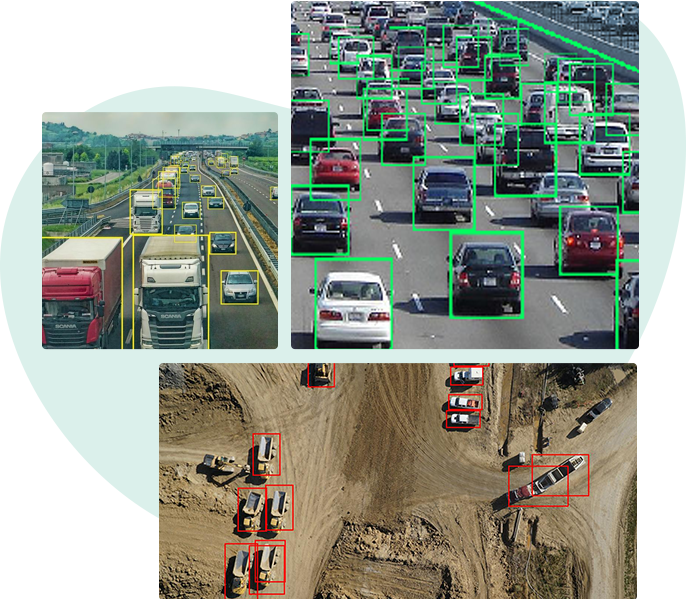
Bounding box annotation helps in object detection, localization, and classification in videos and images. It helps to identify objects by drawing a box around the objects within an image.
Bounding boxes are generally used for image annotations, they offer the next level of accuracy for multiple industries for developing the object recognition perception models. There are multiple use cases for this, the image annotation technique helps the self-driving vehicles recognize their surroundings, to identify the level of damage, making it easier to calculate insurance claims, recognition of various fashion accessories and furniture.
Data labeler is dedicated to delivering the next level of training data for AI and ML backed with bounding box annotation techniques.
Polygons are multipoint annotation techniques to draw shapes, curves and various angles. Polygons help to annotate objects in angled photos and polygons. They mark category annotations for pixels in an image and also label them.
This also has multiple use cases like, identifying street sign boards, facial and pose features in sports analytics, teaching drones to easily navigate through trees and roofs, tackle new horizons in manufacturing and health-care.

Key Points are used to detect small objects and shape variations by creating dots across the image.
This helps with detecting and labeling facial/ skeletal features, expressions, emotions, human body parts, poses, and landmarks that might match your task.

Algorithms use large amounts of annotated data to train AI and ML models. During the annotation process, a metadata tag is used to mark up attributes of a dataset. With regards to text annotation, that data includes tags such as keywords, phrases, or sentences.
Text annotation helps machines to recognize the crucial words in a sentence making it more meaningful and understandable. Annotations for text include a wide range of types, such as relationship, intent, semantic, and sentiment. Data labelers make sure that these tags are accurate and comprehensive. As poorly annotated text can result in issues in clarity or grammatical errors, or lack of clarity.

We offer datasets that empower your models to characterize an image and classify it efficiently and effectively.
The Data Labeler can categorize photos and images at a large scale with a high level of accuracy and efficiency.

Semantic Segmentation is understanding an image at the pixel level and is used in computer-vision based applications that require high accuracy. This classification is when there are more than two categories in which the images can be classified.
This means an image belongs to more than one category and involves the prediction of multiple labels simultaneously associated with a single instance.
